The TEFLON team was glad to organize the Automatic Assessment of Atypical Speech (AAAS) workshop on March 5, 2025 in Tallinn, Estonia. Our workshop was part of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025).
We wish to thank our invited speakers for their interesting talks: Prof. Nina Benway for presenting “What is so hard about AI speech therapy? Evidence from efficacy trials”, and Prof. Ari Huhta for presenting “Automatic assessment of second/foreign language speaking: Review of developments for examination and teaching/learning purposes”.
TEFLON project results were presented by the Finnish, Norwegian, and Swedish project partners. We also heard other interesting presentations. To end the workshop, a panel discussion was held on the future possibilities and affordances of automatic speech assessment. Overall, the workshop was a success, bringing together experts from different disciplines interested in speech and speech technology.
Thanks to all AAAS presenters, panelists, and participants – see you again soon!
Tampere University TEFLON team has run EEG experiments for TEFLON. We are still looking for some children to participate in our gaming intervention and EEG measurements at the Cognitive Brain Research Unit, Helsinki. The experiments also include some reading and speaking tasks.
EEG is a safe method to measure brain activity and it has been used for decades all over the world. With EEG, we measure auditory event-related potentials, that is, brain responses time-locked to auditory stimuli. We expect the responses to show plastic changes in the brain as a result of our gaming intervention.
The gaming intervention includes playing a language learning game Pop2talk Nordic or a math game DragonBox Numbers (https://dragonbox.com/products/numbers). Thank you DragonBox for collaboration!
Sari Ylinen and Timi Tervo gave talks about TEFLON project findings in the meeting of the Finnish Association of Speech and Language Research (Puheen ja kielen tutkimuksen päivät) on 11-12 April 2024 in Helsinki. The theme of the meeting was assessment of speech and language skills, and the use of automatic speech recognition in assessment raised interest. Efforts to further develop automatic assessment of speech and language require multidisciplinary collaboration – something we have already established in the TEFLON project.
I was very pleased to attend Interspeech again this year in Kos, Greece. Kos is a really comfy island located on the east coast of the Aegean sea, almost touching the mainland of Turkey. The conference was held between 01,09 to 05,09, due to this reason the weather is neither too hot nor too cold. Still at noon, it could be warmer if exposed long under the sun but the afternoon breeze can ease the heat.
The main conference takes place at Hippocrates hotel with the name after the famous Greek physician and philosopher. In one of the rooms, I presented my work entitled “A Framework for Phoneme-Level Pronunciation Assessment Using CTC”. Thanks to the practice of the presentation with my professor Prof. Salvi and Prof. Svendsen before coming here, I was not nervous at all. I got a lot of valuable feedback and comments during the 5 mins’ Q&A and after the entire session.
Because my presentation was on Monday morning, I was able to concentrate on other people’s work for the rest of the time. I got inspired a lot from all those great minds and prepared myself a list of literature to read after the conference, really helpful and encouraging! In addition to my two professors at NTNU, I also met Prof. Kurimo and his group from Aalto university. We all noticed that our TEFLON project and our research field, i.e., the concern on child speech, is attracting more and more attention this year. That also strengthened our determination to continuously devote ourselves to this topic.
During one of the evenings when I took a walk in the Kos town, I really fall in love to this place: Kind people, delicious seafood, scenic views, historical buildings and stories etc.
We presented our data collection at Fonetik 2024 in Stockholm, Sweden. The conference also hosted a symposium in celebration of Björn Lindblom 90th birthday.
The abstract can be found here: https://zenodo.org/records/11396068
We presented our data collection effort at the international conference on language resources and evaluation combined with the international conference on computational linguistics (LREC-Coling) in Turin, Italy. The work was well received and we had the possibility to learn about work that is being done in other countries and projects.
Our third face-to-face meeting within the TEFLON project took place in Stockholm, March 20-22. Sofia hosted the meeting at Karolinska Institutet, and the research team got to try out both the Huddinge and the Solna campus of the university.
This time, a total of 13 participants from all project partners – Aalto University, Tampere University, Oslo University, KI and NTNU – were present. The topics for discussion covered updates of learning experiments in Finland, Norway and Sweden, a shared view on user experience from the different experiments, and ideas regarding the use of the collected data. At this stage, most of the data have been collected, and the teams at KI, Tampere and Oslo are now working to process the data and prepare for analysis. This involves a lot of manual perceptual assessment, that will be used to examine potential learning effects for the users of the app. In addition, the manual assessments will be used for re-training the acoustic models that underlie the automatic rating in the app, which we hope will improve the quality of automatic ratings for future users.
In between discussions, we had time for food and drinks.
Another engaging topic during the meeting was ideas for future collaboration, both concerning coming shared publications, and for potential continuation projects. It turns out that we share interests that we were not aware of before! Hopefully, these ideas can turn into future projects!
The research and development that we carry out in the Teflon project relies on collections of speech recordings from foreign children who learn to speak the Nordic languages and from Swedish children with speech sound disorder. This kind of data is unique for several reasons: firstly, no data sets of children speaking Nordic languages are publicly available, as opposed to adult data that is far from scarce. Secondly, we are interested in second language (L2) speakers of Nordic languages, because we want to study how to detect and characterize their mispronunciations. Thirdly, there is no publicly available data of Nordic children with speech sound disorder. Consequently, substantial effort during the project was devoted to collecting such data. This was done both simulating the situation where children play the Pop2Talk game, and, later, recording the game sessions with the students.
The intention when collecting this data was to make all the corpora publicly available, in the spirit of the open science principles. However, we soon realized that the rules defined by the General Data Protection Regulation (GDPR) are interpreted very differently in the different Nordic countries (and, possibly in the other European countries). Those rules have the goal of protecting the privacy of European citizens and refer to any information that may identify each individual. In collections of text, complying with these rules may just mean removing any personal information such as names, telephone numbers, user IDs, or addresses. For speech the situation is more complicated. The main issue regarding speech, is related to the question if the voice is sufficient in order to identify the speaker, and if this, in turns, constitutes sufficient grounds to forbid public sharing of the recordings.
Our experience in Sweden is that different lawyers may interpret the law differently. The lawyers at KI, for example, think it is fine to share recordings of isolated words. But some disagree. When consulting the lawyers at Språkbanken Tal (the main channel for sharing speech data in Sweden), however, their interpretation of the law was much more strict. A similar stricter interpretation is now used in Finland (although publication of speech data from individuals over 16 years has been permitted in the past). In contrast, in Norway, the rules are interpreted to only apply to what is spoken, and not to the voice that speaks. As a result, of the many corpora that we recorded for Finnish, Swedish and Norwegian as target languages, we will only be able to publish the Norwegian corpus.
The different responses to our requests to the ethical committees in the different countries illustrate the complexity of speech data sharing. It is useful to stress that the L2 data sets for Swedish, Norwegian and Finnish were completely equivalent in all respects: age of participants, characteristics of the participants, content of the recordings, anonymization of the participants in the metadata, sharing conditions requested, to name a few. It is also important to point out that the characteristics of child voice, that may allow the identification of an individual, change very quickly with age. This means that the participants will not be identifiable by their voice in just a few months or years after the recordings. We hope that, in the future, uniform interpretations of regulations and practices in handling speech data will be introduced. We believe that the availability of open-access speech corpora with child speech is of essential value for scientific research and speech technology development, and they will bring about great advantages for society.
We have submitted a paper describing the data collected in the Teflon project in more detail to the LREC2024 conference that will take place in Turin, Italy, on May 20-25. Please visit the LREC2024 website for more information.
The Computational Paralinguistics Challenge (ComParE) was organized as part of the ACM Multimedia 2023 conference. The annual challenge deals with states and traits of individuals as manifested in their speech and further signals’ properties. Each year, the organizers introduce tasks, along with data, for the participants to develop solutions.
Our team, consisting of PhD students: Dejan Porjazovski, and Yaroslav Getman, as well as the Research Fellow Tamás Grósz and Professor Mikko Kurimo, participated in the two challenges provided by the organizers:
Requests and Emotion Share.
The Requests sub-challenge involves real interactions in French between call centre agents and customers calling to resolve an issue. The task is further divided into two sub-tasks: Determine whether the customer call concerns a complaint or not, and whether the call concerns membership issues or a process, such as affiliation.
The multilingual Emotion Share task, involving speakers from the USA, South Africa, and Venezuela, tackles a regression problem of recognising the intensity of 9 emotions present in the dataset. The intensities of the emotions that need to be recognized are anger, boredom, calmness, concentration, determination, excitement, interest, sadness, and tiredness.
Our team tackled these issues by utilizing the state-of-the-art wav2vec2 model, along with a Bayesian linear layer. The choice for the appropriate wav2vec2 model, along with the best-performing transformer layer, and the Bayesian linear layer, led to our team winning the Emotion Share sub-challenge:
Simultaneously, we also participated in the 4th Multimodal SentimentAnalysis Challenge. The team consisted of PhD students Anja Virkkunen and Dejan Porjazovski, together with Research Fellow Tamás Grósz and Professor Mikko Kurimo.
We chose to tackle two extremely hard problems: Humour and Mimicked Emotions detection using videos. Our solution focused on large, pre-trained models, and we developed a method that could identify relevant parts outputs of these foundation models, making them a bit more transparent. The empirical results demonstrate that these large AIs have smaller specialized outputs that contain relevant information for detecting jokes and emotions of the speakers based on visual and audible cues.
Etsimme osallistujia yhteispohjoismaiseen tieteelliseen tutkimukseen, jossa tutkitaan lasten kielen oppimista oppimispelien avulla. Tampereen yliopistossa ja Aalto-yliopistossa tutkitaan pelisovelluksia, joilla voi harjoitella vierasta kieltä tai matematiikkaa. Tämä tutkimus on jatkoa vuonna 2016 alkaneelle lasten digitaalisen oppimisen tutkimukselle, jossa on aiemmin tutkittu mm. lasten englannin kielen oppimista äänipohjaisten sovellusten avulla.
Tutkimuksen mittaukset tapahtuvat Helsingissä.
Kutsumme mukaan tutkimukseen ekaluokkalaisia ja esikoulussa olevia lapsia, joiden äidinkieli on suomi, ja jotka eivät vielä puhu sujuvasti ruotsia tai englantia. Osa lapsista pelaa kielenoppimispeliä ja osa puolestaan pelaa DragonBox Numbers -matematiikkapeliä.
Pyydämme kiinnostuneita ottamaan yhteyttä sähköpostitse: anna.2.smolander@tuni.fi
The TEFLON studies in Oslo, Norway, focus on investigating how gaming interventions affect immigrant children’s development and language learning. We have recently launched data collection at schools in Oslo and surrounding communities. The study is being coordinated by the doctoral researcherAnne Marte Haug Olstad.
We are inviting pupils at so-called Welcome Classes (Velkomstklasser / Mottaksklasser) to participate in the study. Pupils in these classes have recently arrived in Norway, have varying language backgrounds, and are in the early phases of learning Norwegian.
Within this study, the kids get a chance to play educational games, such as our recently developed language learning game “Pop2Talk Norwegian” and the “Dragonbox” maths game (https://dragonbox.com/). They get to play the games 4-5 times per week for 4 weeks during school hours.
Photo credit: Anna Smolander
For the research, we are testing children’s language and cognitive skills and how playing the games may help their learning and skill development. The testing is currently being conducted at the schools. We are also planning to invite some pupils to take part in an EEG experiment and measure how children’s brain responses are affected by the learning. This study will take place at the Socio-Cognitive Laboratory at University of Oslo in Blindern.
We are thankful to all the participants as well as the engaged teachers in these classes for making this research possible!
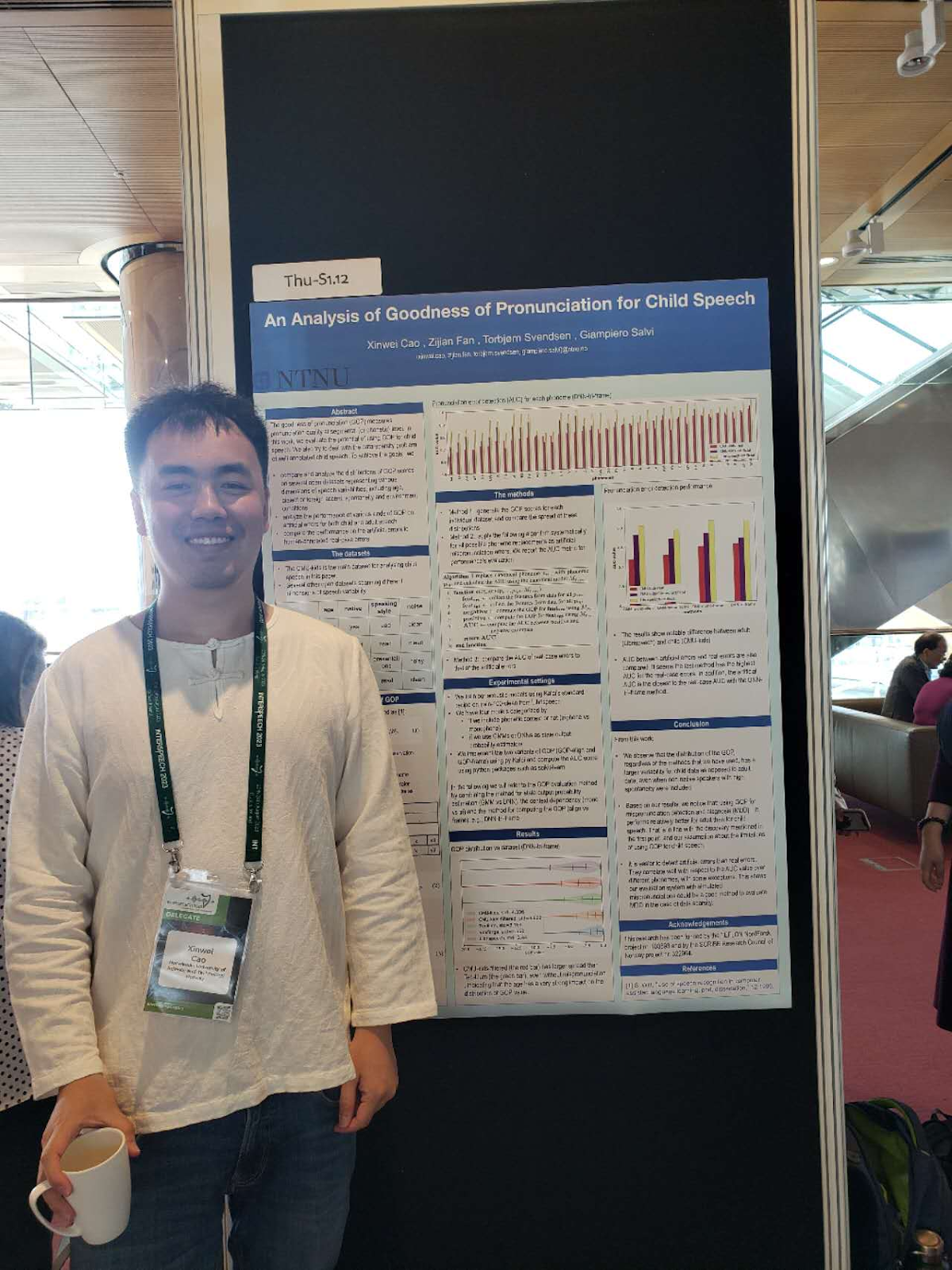
Hi, my name is Xinwei. I am a second year Phd student within the TEFLON project. I was very happy and excited about attending the INTERSPEECH 2023 from 20.August to 24.August in Dublin.
It was my first time joining such an international and well-known conference. In this conference I met a lot of senior researchers from all over the world in the fields of speech and signal processing that includes my supervisor Prof. Torbjørn Karl Svendsen. I also met Prof. Mikko Kurimo from the university of Aalto and many of the other members in our project during this conference.
There were so many interesting ideas and techniques being proposed this year. I just wished to clone several of myself in order to be the audience of several parallel presentations, instead of running from one room to another all over the building. I also noticed many inspirational posters that inspired me for my research fields. In addition, I also encountered some of the posters with which I was not familiar with, e.g., speech synthesis and speech enhancement. It was really amazing to talk to those presenters and grasp the main concepts and problems of those fields in half an hour’s time.
I also presented our work with the title “An Analysis of Goodness of Pronunciation for Child Speech”. Thanks to many questions and advice from the audiences, I am now having a clearer picture of my future research work.
Really amazing conference. Can’t wait to meet all of you next year!
Hi, I’m Nhan Phan, a PhD student at Aalto University. I’m part of the Teflon project, and my role is to maintain the Pop2Talk Nordic mobile application. Pop2Talk is a language learning game that allows children to imitate words that were said during the game progress, and get a rating of their pronunciation. Based on the original game version intended for English, the Pop2Talk Nordic version expanded to Nordic languages. As I write this blog post, we have successfully developed four different versions of the game. These include:
A Finnish version for children who find it challenging to pronounce the phoneme “R”.
A Swedish version for children with Speech Sound Disorder.
And two other versions for children who want to learn Norwegian or English.
While much of the project’s foundational work was led by experienced partners in children’s speech-language pathology and in automatic speech recognition technology, I was fortunate to be involved in the project, being responsible for the design and maintenance of both the server and the mobile game.
With our need for illustrations in multiple languages, we turned to the latest AI technology for automatic image generation. I provided our partners with technical instructions on crafting text prompts to ensure the resulting images were both captivating and child-friendly. To my surprise, the images they produced were outstanding, surpassing all my expectations. Check out this cool picture from Magdalena at Karolinska Institutet. Funny thing, the girl is the spitting image of my 2-year-old daughter. I had to ask right away to use it as my daughter’s avatar.
When I showed the game to my daughter, she was super into it—even though she’s just starting to learn Finnish. She got so hooked that I had to yank the phone from her! I really hope other kids get just as excited when they play (and fingers crossed, they’ll want to take a break after a while).
As we move into October, we’re preparing for numerous experiments. These will study how children acquire vocabulary and pronunciation, and evaluate the game’s effectiveness in helping them. Those experiments will be conducted in various schools across Finland, Sweden and Norway. My primary focus at the moment is to ensure the server runs without any serious problems.
On the 12th of October 2023, Giampiero Salvi presented the work carried out in Teflon at the Nordic Network for L2 Pronunciation (NNL2P) in Trondheim. The workshop had a number of very interesting keynote speakers that brought long experience and insights in the field of pronunciation assessment. The Teflon presentation was very well received. Please the workshop website for more information.
After 4 years without meetings the SLaTE met again at Trinity College in Dublin in August 2023 just before the ISCA’s main event INTERSPEECH 2023. TEFLON partners had three presentations in SLaTE and one in its sister workshop SIGUL 2023 that was run parallel to it in another nearby meeting room.
On the 20th-21st of June, 12 researchers from Aalto University, Tampere University, Karolinska Institutet, University of Oslo and NTNU gathered at the Campus of NTNU for the second face-to-face meeting of the Teflon project.
As for the first physical meeting, we had two full days including discussion sessions about the data, evaluations, automatic speech recognition, game design, automatic and human pronunciation assessment, experiment design, publications, dissemination and project management. The game was already in a mature state of development, so much of the discussion was devoted to planning the experiments with school children in the three countries. On Tuesday evening we continued after the meeting to have dinner in downtown Trondheim and enjoy the good company and delicious food in the restaurant To Rum og Kjokken where we had a room all to ourselves. We also took a long walk through the city in the light of the night sun.
The next steps in the project include running the experiments with the children, collecting new data from the experiments and analyzing it.
Written by: Sofia Strömberggson, Karolinska Institut
An important feature of the speech training app developed in TEFLON is to provide children with feedback concerning their speech production. This feedback will be presented as stars, with 5 stars representing “correct” pronunciation, and the fewer stars, the further away from “correct”. But how does the app know how many stars to present for a given utterance? In fact, this is something that the app (or rather, the acoustic model within the app) has to learn from how humans have evaluated children’s utterances.
But even for humans, the task of evaluating the correctness of children’s utterances is not trivial. For one, there are very many ways for utterances to be “correct”. (And that is a good thing when it comes to human perception in daily life! It means that we can “tolerate” a lot of variation in speech production without communication being too easily disrupted.) But also, there are even more ways that utterances can be “incorrect”. For example, is the utterance still intelligible as the intended word? And for intelligible utterances – are one or more speech sounds affected? Are different types of speech errors more severe than others? In TEFLON, the different research teams have tackled this challenge in slightly different ways.
At Karolinska Institutet, the human evaluators have used the same 1-5 scale that will be used in the app. In an effort to ensure consistency in the evaluations, the following rating key was specified:
not at all identifiable as the target word
not identifiable as the target word
slight phonemic error (e.g., the target word “kollision” is pronounced “kolliton”)
subphonemic error/”unexpected variant” (e.g., the /r/-sound in “ros” is not quite produced as you’d expect)
prototypical/adult-like/correct
But even with this rating key, the evaluation decisions are not always easy. The researchers are currently running listening experiments with more listeners – experts (in this context: speech-language pathologists) and non-experts – to explore listener behaviors more systematically. For this task, the listeners are instructed to rate the utterances from 1 to 5 as they think the app should rate the utterance (i.e., without being provided with a rating key). Through these experiments, the researchers hope to learn more concerning whether expert and non-experts differ in their ratings, and whether listener ratings are more consistent for listeners who have access to “reference samples” when conducting their evaluations. The researchers aim to present their findings later during 2023.
The ACM Multimedia 2022 Computational Paralinguistics ChallengE (ComParE) is an open Grand Challenge dealing with states and traits of speakers as manifested in their speech signal’s properties and beyond. At the start of the competition, the data is provided by the organizers, and the Sub-Challenges are generally open for participation.
This year our team, consisting of PhD students (Yaroslav Getman and Dejan Porjazovski), Research Fellows (Tamás Grósz and Sudarsana Reddy Kadiri), and Professor Mikko Kurimo, embarked on tackling two Sub-Challenges: the Vocalisations and the Stuttering one.
In the Stuttering Sub-Challenge, participants were tasked to develop a system that can recognize different kinds of stuttering (e.g. word/phrase repetition, prolongation, sound repetition and others). Stuttering is a complex speech disorder with a crude prevalence of about 1 % of the population. Monitoring of stuttering would allow objective feedback to persons who stutter (PWS) and speech therapists, thus facilitating tailored speech therapy, with the automatic detection of different stuttering phenomena as a necessary prerequisite. As training data, we could use the Kassel State of Fluency corpus containing approximately 5600 annotated samples.
In the Vocalisations Sub-Challenge, non-verbal vocal expressions (such as laughter, cries, moans, and screams) from the Variably Intense Vocalizations of Affect and Emotion Corpus are used for classifying the expression of six different emotions. Such human non-verbals are still understudied but are ubiquitous in human communication. This task was extremely challenging because the training data contained only female voices, while the developed systems were evaluated on male sounds.
Our team developed solutions for both tasks using state-of-the-art models like wav2vec 2.0, data augmentation and other simple tricks based on the distributed training data. For technical details, see our paper:
Tamás Grósz, Dejan Porjazovski, Yaroslav Getman, Sudarsana Kadiri, and Mikko Kurimo. 2022. Wav2vec2-based Paralinguistic Systems to Recognise Vocalised Emotions and Stuttering. In Proceedings of the 30th ACM International Conference on Multimedia (MM ’22). Association for Computing Machinery, New York, NY, USA, 7026–7029. https://doi.org/10.1145/3503161.3551572
In total, 23 teams from all around the world registered for the competition, of which 8 submitted solutions for the Stuttering, and 11 for the Vocalisations Sub-Challenge.
Aalto’s team won both competitions, earning two spaces in the hall of fame:
The 23rd INTERSPEECH Conference took place from September 18 to 22, 2022, at Songdo ConvensiA, in Incheon, Korea, under the theme Human and Humanizing Speech Technology. INTERSPEECH is the world’s largest and most comprehensive conference on the science and technology of spoken language processing. INTERSPEECH conferences emphasize interdisciplinary approaches addressing all aspects of speech science and technology, ranging from basic theory to advanced applications.
Truly a city of the future, Songdo sits adjacent to Seoul, regarded as one of the technology capitals of the world. The city’s underground railway already offers high-speed WiFi, with electronic panels at the exits and provides the waiting time for connecting to buses or trains, while companies like Samsung Electronics are already working on linking household devices to mobile phones. On the technological front, Songdo is a brand-new city that offers the chance to integrate innovation into daily life truly.
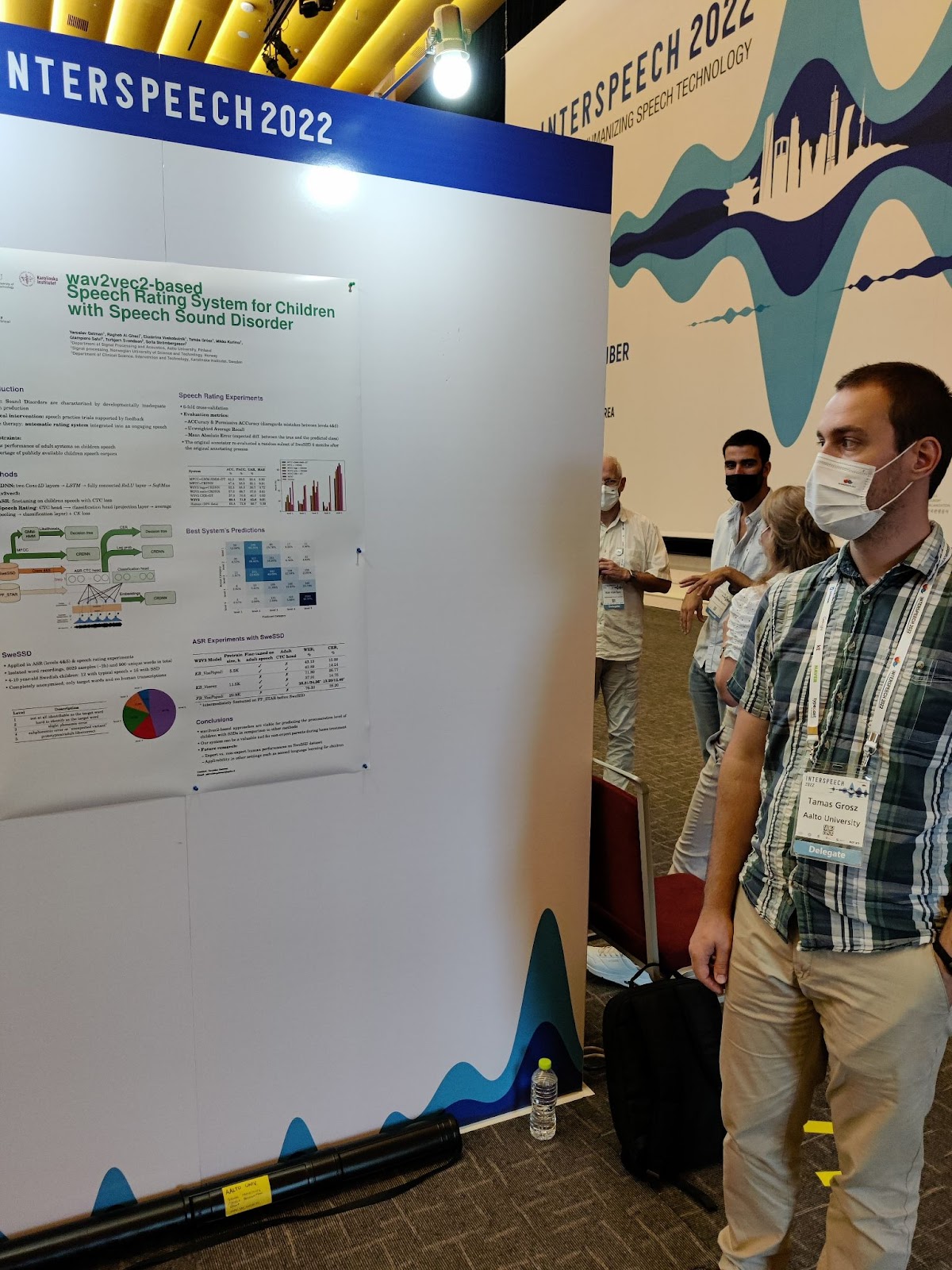
This year, the Teflon team submitted a paper titled “wav2vec2-based Speech Rating System for Children with Speech Sound Disorder” to Interspeech. The article described our initial systems developed using Sofia Strömbergsson’s corpus of children suffering from speech sound disorder. Speech therapies, which could aid these children in speech acquisition, greatly rely on speech practice trials and accurate feedback about their pronunciations. Our solutions could be the basis for software tools that would enable home therapy and lessen the burden on speech-language pathologists. Our submission was accepted with very positive reviews and selected for a poster presentation.
We (Tamás & Mikko) presented our poster on Wednesday, September 21, 13:30-15:30(KST). We were lucky enough to be placed right in front of the main entrance, resulting in many people stopping at our stand to check the poster.
We had several very intriguing conversations and gained some valuable ideas and suggestions from our colleagues, which we will explore in the future. After a fruitful poster session, we let some steam off during the gala banquet, where we had the chance to sample Korean cuisine and listen to some authentic K-POP music.
Sources:
https://www.interspeech2022.org/general
Getman, Y., Al-Ghezi, R., Voskoboinik, K., Grósz, T., Kurimo, M., Salvi, G., Svendsen, T., Strömbergsson, S. (2022) wav2vec2-based Speech Rating System for Children with Speech Sound Disorder. Proc. Interspeech 2022, 3618-3622, doi: 10.21437/Interspeech.2022-10103
In 5-6 September, 15 researchers of Aalto University, Tampere University, Karolinska Institutet, University of Oslo and NTNU (Trondheim) gathered in the Campus of Aalto University for the first face-to-face meeting of the Teflon project. The project has been running already for almost 1.5 years, but due to the pandemic, our kick-off and all other meetings have been only virtual. Actually 4 of us still had to participate remotely due to sudden Covid-19 cases in NTNU’s team etc, but for the rest this was a really delightful experience to meet and have in-depth discussions of the project, science, technology and everything else.
We had two full days including discussion sessions about the data, evaluations, automatic speech recognition, game design, automatic and human pronunciation assessment, experiment design, publications, dissemination and project management. Because we were still in the early stages of building the children’s pronunciation game, collecting and annotating the data and training the automatic assessment, the focus was clearly on planning the next steps of the project. On Monday evening we continued after the project to have dinner in downtown Helsinki and enjoy the good company and delicious food in the restaurant Emo.
The next steps in the project include finishing the game codes, developing multitask systems and faster speech processing servers, repeating the previously run tests on the new Finnish, Swedish and Norwegian data, finishing the human assessments for these data, fix word lists and other specs for the game for each language, and recruiting speakers for the remaining training data.