The ACM Multimedia 2022 Computational Paralinguistics ChallengE (ComParE) is an open Grand Challenge dealing with states and traits of speakers as manifested in their speech signal’s properties and beyond. At the start of the competition, the data is provided by the organizers, and the Sub-Challenges are generally open for participation.
This year our team, consisting of PhD students (Yaroslav Getman and Dejan Porjazovski), Research Fellows (Tamás Grósz and Sudarsana Reddy Kadiri), and Professor Mikko Kurimo, embarked on tackling two Sub-Challenges: the Vocalisations and the Stuttering one.
In the Stuttering Sub-Challenge, participants were tasked to develop a system that can recognize different kinds of stuttering (e.g. word/phrase repetition, prolongation, sound repetition and others). Stuttering is a complex speech disorder with a crude prevalence of about 1 % of the population. Monitoring of stuttering would allow objective feedback to persons who stutter (PWS) and speech therapists, thus facilitating tailored speech therapy, with the automatic detection of different stuttering phenomena as a necessary prerequisite. As training data, we could use the Kassel State of Fluency corpus containing approximately 5600 annotated samples.
In the Vocalisations Sub-Challenge, non-verbal vocal expressions (such as laughter, cries, moans, and screams) from the Variably Intense Vocalizations of Affect and Emotion Corpus are used for classifying the expression of six different emotions. Such human non-verbals are still understudied but are ubiquitous in human communication. This task was extremely challenging because the training data contained only female voices, while the developed systems were evaluated on male sounds.
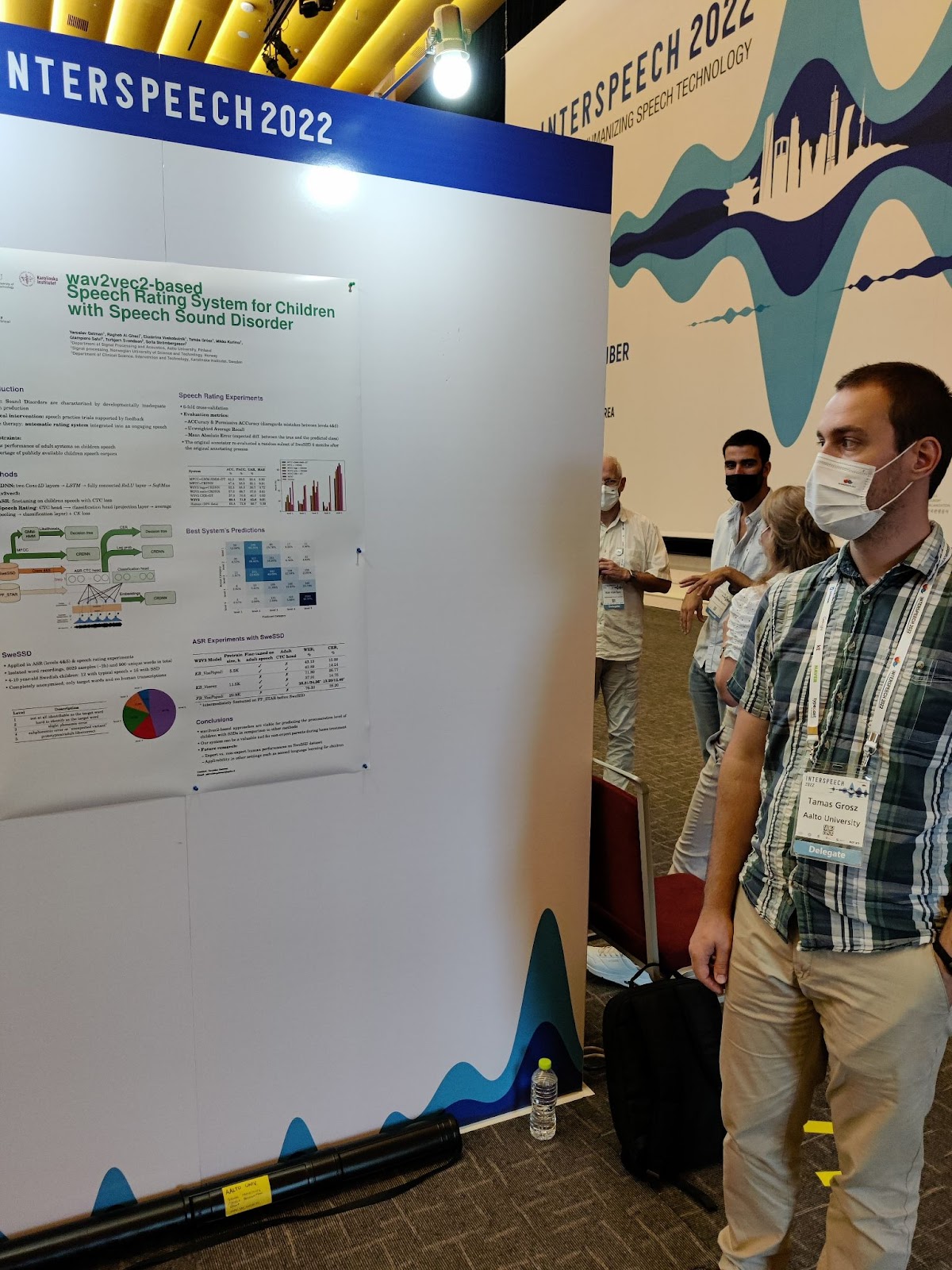
Our team developed solutions for both tasks using state-of-the-art models like wav2vec 2.0, data augmentation and other simple tricks based on the distributed training data. For technical details, see our paper:
Tamás Grósz, Dejan Porjazovski, Yaroslav Getman, Sudarsana Kadiri, and Mikko Kurimo. 2022. Wav2vec2-based Paralinguistic Systems to Recognise Vocalised Emotions and Stuttering. In Proceedings of the 30th ACM International Conference on Multimedia (MM ’22). Association for Computing Machinery, New York, NY, USA, 7026–7029. https://doi.org/10.1145/3503161.3551572
In total, 23 teams from all around the world registered for the competition, of which 8 submitted solutions for the Stuttering, and 11 for the Vocalisations Sub-Challenge.
Aalto’s team won both competitions, earning two spaces in the hall of fame: